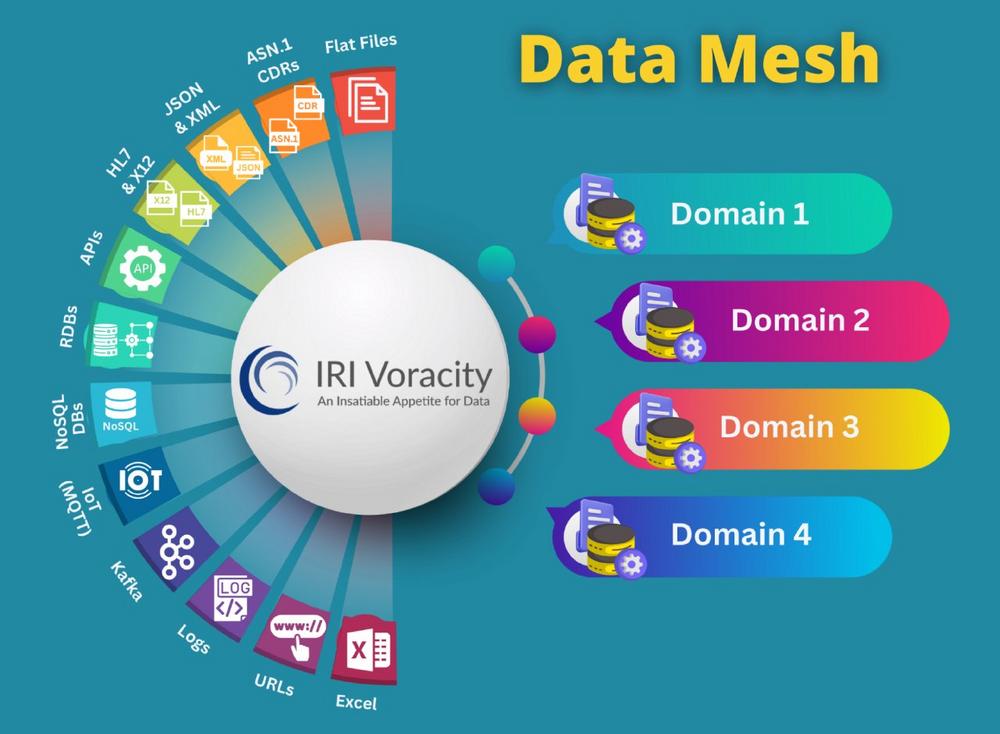
Die Einführung eines Data Mesh stellt einen modernen und vielversprechenden Ansatz dar, um Herausforderungen traditioneller, zentralisierter Datenarchitekturen zu begegnen. Die Idee dahinter: Daten sollen nicht mehr ausschließlich durch zentrale IT-Abteilungen verwaltet werden, sondern dort entstehen und gepflegt werden, wo sie gebraucht und verstanden werden – in den jeweiligen Fachabteilungen.
Der Data-Mesh-Ansatz basiert auf vier zentralen Prinzipien:
- Domänenorientierte, dezentrale Datenverantwortung
- Daten als Produkt
- Self-Service-Dateninfrastruktur
- Föderierte Governance
Diese Prinzipien stärken die Eigenverantwortung von Fachbereichen, fördern die Interoperabilität und stellen sicher, dass Unternehmensdaten vertrauenswürdig, zugänglich und wiederverwendbar bleiben. Die Herausforderung dabei liegt nicht nur in der technischen Umsetzung, sondern auch in kulturellen und organisatorischen Veränderungen. Um Data Mesh erfolgreich zu implementieren, braucht es klare Verantwortlichkeiten, die richtigen Werkzeuge – und eine Plattform, die diese Grundprinzipien unterstützt.
IRI Voracity ist genau eine solche Plattform. Sie vereint leistungsfähige Funktionen zur Datenintegration, Migration, Governance, Profilierung, Maskierung und Analyse in einer konsistenten Umgebung. Dabei unterstützt Voracity nicht nur klassische Architekturen, sondern lässt sich flexibel in moderne Konzepte wie Data Mesh integrieren.
Skalierbarkeit, Qualität und Geschwindigkeit – Die Vorteile im Überblick
Der Data-Mesh-Ansatz kann die Skalierbarkeit, Agilität und Datenqualität in Organisationen deutlich verbessern. Durch die Dezentralisierung der Datenverantwortung werden Engpässe reduziert, Entscheidungen beschleunigt und die Datenkompetenz in den Fachabteilungen gestärkt. Wenn Daten wie Produkte behandelt werden, steigt das Bewusstsein für deren Qualität und Relevanz – was wiederum zuverlässige Analysen und Innovation fördert.
Mit Self-Service-Infrastruktur ermöglicht Voracity es Teams, eigenständig mit Daten zu arbeiten – ohne immer auf zentrale IT-Ressourcen angewiesen zu sein. Dies unterstützt kollaboratives Arbeiten ebenso wie eine stärkere Daten-Demokratisierung im Unternehmen.
IRI Voracity bietet zahlreiche Funktionen, die zentral für ein funktionierendes Data Mesh sind:
- Datensuche, -klassifikation, Profiling und Qualitätssicherung
- Datenmaskierung, -bereinigung und Zugriffskontrolle
- Versionierung von Datenprodukten über Git-Repositories
- Unterstützung polyglotter Datenquellen und -ziele (strukturierte, semi-strukturierte und unstrukturierte Daten)
- Pipelines, CI/CD-Integration und skalierbare Datenverarbeitung (horizontal wie vertikal)
Mit der webgestützten Oberfläche DataSwitch bietet Voracity zudem Self-Service-Funktionen, die die Erstellung, Kontrolle und das Teilen von Datenprodukten benutzerfreundlich gestalten.
Governance und klare Datenverantwortung schaffen
Ein zentrales Problem in vielen Data-Mesh-Implementierungen ist die unklare Datenverantwortung: Wenn verschiedene Teams mit unterschiedlichen Versionen desselben Datensatzes arbeiten, entstehen widersprüchliche Ergebnisse und Vertrauensverluste.
Hier bietet Voracity mit seinen FAIR-Metadaten (Findable, Accessible, Interoperable, Reusable) und der Entwicklungsumgebung IRI Workbench auf Eclipse-Basis eine Lösung. Datenquellen, Transformationen und Reports werden dort eindeutig dokumentiert und versioniert. Die Zuordnung von Datenprodukten zu bestimmten Domänen sorgt für Klarheit bei Verantwortlichkeiten und erlaubt eine effiziente Zusammenarbeit von Engineering- und Business-Teams.
POCs leicht gemacht – Einstieg in den Data Mesh
Durch seine modulare Architektur und hohe Flexibilität eignet sich Voracity auch für schnelle Proof-of-Concepts (POCs). Unternehmen können mit kleinen Projekten testen, wie sich Data Mesh konkret umsetzen lässt – von der Erstellung erster Datenprodukte bis zur vollständigen Integration von Governance- und Sicherheitsprozessen.
Die Vorteile liegen auf der Hand:
Mit IRI Voracity lassen sich datengetriebene Prozesse beschleunigen, IT-Backlogs abbauen, Datenverantwortung dezentral organisieren und gleichzeitig Datensicherheit sowie Compliance sicherstellen.
Fazit: Mit Voracity zum erfolgreichen Data Mesh
Ein Data Mesh ist mehr als eine technische Architektur – es ist ein organisatorisches Paradigma, das Verantwortung, Effizienz und Zusammenarbeit neu definiert. IRI Voracity liefert die Werkzeuge, um diesen Wandel sicher und performant zu gestalten. Ob für große Transformationsprojekte oder gezielte Optimierungen: Die Plattform ermöglicht eine kontrollierte, skalierbare und produktorientierte Datenverarbeitung, die zentralen wie dezentralen Anforderungen gerecht wird.
Effiziente Datenverarbeitung: Unsere bewährte Software für Datenmanagement und Datenschutz vereint modernste Technologien mit über 40 Jahren Erfahrung in der zuverlässigen Verarbeitung von Produktionsdaten – plattformunabhängig und branchenübergreifend.
Seit 1978 im B2B-Sektor: Namhafte Unternehmen, führende Dienstleister, Banken, Versicherungen sowie Landes- und Bundesbehörden setzen seit Jahrzehnten auf unsere Software und Expertise. Weltweite Referenzen sind hier zusammengefasst – deutsche Referenzen sind hier gelistet.
Maximale Kompatibilität: Unsere Software läuft effizient auf allen wichtigen Betriebssystemen – auf Mainframe-Systemen (Fujitsu BS2000/OSD, IBM z/OS, z/VSE und z/Linux) und Open Systems wie Linux, UNIX-Derivaten und Windows.
Sparen Sie Zeit und Geld bei der Manipulation oder dem Schutz Ihrer Daten mit unserer bewährten Low-Code-Datenmanagement- und Maskierungssoftware. Wir verbinden modernste Technologie mit jahrzehntelanger Erfahrung in der Verarbeitung von Produktionsdaten auf verschiedenen Plattformen und in unterschiedlichen Branchen.
Mit unserer Software können Sie:
Große Sortier- und ETL-Aufträge beschleunigen
Beschleunigung von Datenbank-Entladungen, -Ladungen, -Reorgs und -Abfragen
Konvertieren und Neuformatieren von alten Datentypen, Dateien und Datenbanken
Erstellung benutzerdefinierter Berichte oder Aufbereitung von Daten für Analysen und KI
Ersetzen von alten ETL-, SQL- und Sortieraufträgen
Suchen, Extrahieren und Restrukturieren unstrukturierter Daten
Replizieren und Erfassen geänderter Datenbank-Daten in Echtzeit
Filtern, Bereinigen, Anreichern und Standardisieren von Daten
PII klassifizieren, entdecken und de-identifizieren
Daten statisch, dynamisch oder inkrementell maskieren
PHI-Re-ID-Risiko bewerten und Quasi-Identifikatoren anonymisieren
Synthetisieren von strukturell und referenziell korrekten Testdaten
Profitieren Sie von der Leistungsfähigkeit und Flexibilität der preisgekrönten IRI-Lösungen, die von Analysten beraten und durch 40 Partnerbüros weltweit unterstützt werden. Vermeiden Sie die steile Lernkurve und die hohen Kosten von Multi-Tool- und Mega-Anbieter-Lösungen und entdecken Sie die Vorteile schnellerer Design- und Laufzeiten für Ihr Unternehmen.
Die spezifischen Lösungen sind kompatibel mit allen gängigen Betriebssystemen, vom Mainframe (Fujitsu BS2000/OSD, IBM z/OS und z/VSE + z/Linux) bis hin zu Open Systems (UNIX & Derivate, Linux + Windows).
Seit 1978 weltweit anerkannt im B2B-Sektor: Großunternehmen, nationale und internationale Dienstleister, Privat-, Groß-, Landes- und Bundesbanken, Sozial- und Privatversicherungen sowie deutsche, Landes- und Bundesbehörden!
JET-Software
Edmund-Lang-Straße 16
64832 Babenhausen
Telefon: +49 (6073) 711-403
Telefax: +49 (6073) 711-405
https://www.jet-software.com
Telefon: +49 (6073) 711403
Fax: +49 (6073) 711405
E-Mail: amadeus.thomas@jet-software.com
![]()